רבים נוטים לחשוב ש-Power BI מוגבל ביכולתו להתמודד עם כמויות גדולות במיוחד של נתונים.
עם זאת, באמצעות תכנון ארכיטקטורה נכון, ניתן להקים מערכת יעילה לעיבוד וניהול כמויות נתונים גדולות.
במאמר זה נסקור דוגמה למבנה הארכיטקטורה האפשרי לפיתוח מודלי נתונים גדולים באמצעות Power BI.
נתחיל בהסבר על המונחים הבסיסיים, נבחן את השלבים השונים בבניית מודל נתונים רחב היקף, נדון בתשתית הנדרשת, כולל תכנון ובחירת כלים, ונעמיק בשיטות עבודה מומלצות לעיבוד וניהול כמויות נתונים גדולות.
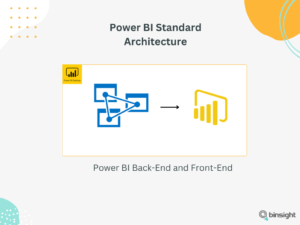
Power BI Front-End VS Back-End
כמו טכנולוגיות ומערכות מידע אחרות, גם את Power BI ניתן לחלק לשני חלקים עיקריים
את Power BI, בדומה לכל טכנולוגיות ומערכות טכנולוגיות, ניתן לחלק לשני מרכיבים עיקריים:
Front-End – החלק שבו המשתמשים מתקשרים עם המערכת. זה כולל את כלי הדוחות והדשבורדים האינטראקטיביים שמאפשרים למשתמשים להציג, לנתח, ולחקור את הנתונים.
Back-End – החלק שבו מתבצעת כל עבודת עיבוד הנתונים והאינטגרציה עם מקורות הנתונים השונים.
זה כולל את ה Power Query, מנוע ה DAX (Data Analysis Expressions) והמודל הנתונים.
כאן מתבצעת כל העבודה של שאיבת הנתונים ממקורות שונים, ניקוי והכנת הנתונים, ויצירת המודל הטבולרי המאפשר את האנליטיקה והניתוח המעמיק של הנתונים.
במאמר זה אנו נתמקד ב BE של Power BI, ונביע מדוע ההפרדה בין ה FE ל BE עושה את כל ההבדל.

Microsoft Analysis Services (SSAS)
אז, SSAS הוא מנוע אנליטי חזק המאפשר לעבד ולנתח כמויות גדולות של מידע. הגרסה העננית של מוצר זה נקראת AAS (Azure Analysis Services). במאמר זה נתייחס ל AAS.
OLAP
בעבר, מודלים שהוקמו ב SSAS נקראו OLAP (Online analytical processing) והשתמשו בעיבוד אנליטי רב מימדי.
מודלים אלו איפשרו אחסון נתונים בצורה של קוביות רב-ממדיות, מה שהביא לביצועים מהירים מאוד של שאילתות בזכות האחסון האופטימלי, אינדוקס רב-ממדי, וזיכרון מטמון.
שפת התשאול של קוביית ה OLAP נקראת MDX (multidimensional expressions).
Tabular
עם הזמן, נוספו גם מודלים טבולריים, שנחשבים לפשוטים יותר לשימוש וניהול. בהתחלה מייקרוסופט קידמה את שתי הטכנולוגיות (OLAP and Tabular), אך בשלב כלשהו נזנח מודל ה OLAP ומייקרוסופט הכריזה עליו כלגאסי.
שפת התחקור של המודל הטאבולרי היא DAX (Data Analysis Expressions). מוכר לכם?
המודל הטבולרי ב AAS מציע יכולות מתקדמות לניתוח נתונים מורכבים ולקבלת תובנות עסקיות באופן יעיל.
המודל מאפשר יבוא נתונים טבלאיים ממקורות שונים, יצירת קשרים בין טבלאות, והגדרת מדדים ועמודות מחושבות באמצעות שפת DAX.
כמו כן, ניתן ליצור היררכיות בתוך המודל, המאפשרות ניתוח נתונים ברמות פירוט שונות, בהתאם לצרכים האנליטיים.
תכונות אלו מאפשרות ביצוע ניתוחי נתונים מעמיקים, יעילים ומהירים. מוכר לכם?
איך PBI קשור?
כשאנו יוצרים מודל נתונים ב PBI, מאחורי הקלעים נוצר לנו מודל טאבולרי וניתן להתחבר אליו גם באמצעות AAS.
בעצם, PBI משמש כממשק ידידותי ליצירת מודל טאבולרי, אך מעט מנוון יותר.
ואיך כל זה קשור לנושא המאמר?
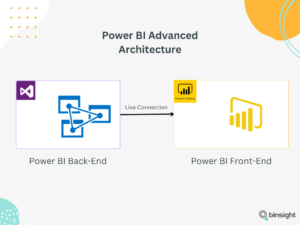
בפרוייקטי BIG DATA עם PBI, נדרש ניהול מעמיק יותר של המודל הטבולרי מה שלא מתאפשר באמצעות הממשק של PBI.
לכן במקרים אלו, אנו נקים וננהל את המודל באמצעות AAS, ו PBI יחובר ב Live Connection למודל הטאבולרי.
הפרד ומשול
משמע, פיצלנו את המודל שעד כה הכרנו ב PBI לשתי טכנולוגיות. AAS אחראי על ה BE, ו PBI אחראי כמובן על ה FE.
כעת נוכל להקצות משאבים לכל אחד מהם בנפרד בהתאם לצרכים וכמובן שהדגש העיקרי הוא ה BE, לפחות בהקשר של מאמר זה.
AAS מאפשר ניהול מודל טבולרי מתקדם ומתוחכם יותר.
הוא מספק יכולות ניהול ואופטימיזציה משופרות, יכולות עיבוד מהירות יותר, וכלי ניהול מתקדמים נוספים.
מודל טבולרי ב AAS מנוהל באמצעות Microsoft Visual Studio עם הרחבות Analysis Services Projects and SSDT.
כלים אלו מאפשרים למשתמשים לעצב, לפתח ולפרוס מודלים טבולריים ב-AAS.
הם מספקים סביבה אינטואיטיבית לעבודה עם מודלים של נתונים, כולל יכולות מתקדמות ליצירת מדדים, חישובים ויחסים בין טבלאות, תוך תמיכה מלאה בשפת DAX לביצוע ניתוחים מורכבים ויעילים של נתונים.
היתרון העיקרי בשימוש ב AAS הוא התמיכה במדרגיות גבוהה (High Scalability)- היכולת להוסיף משאבים באופן דינמי, כמו מעבדים נוספים וזיכרון, כאשר הדרישות גדלות, ומצד שני, להקטין את המשאבים כאשר הצורך פוחת, כדי לחסוך בעלויות ולשמור על יעילות.
עוד פונקציה משמעותית ב-AAS היא היכולת ליצור ולחלק את הנתונים למחיצות (Partitions).
חלוקת הנתונים למחיצות מאפשרת עיבוד וטעינת נתונים יעילים יותר, שכן ניתן לטפל בכל מחיצה בנפרד ולאפשר ביצועים אופטימליים גם עבור מערכי נתונים גדולים.
מחיצות מאפשרות גם ניהול טוב יותר של עומסי עבודה ותחזוקה קלה יותר של הנתונים, על ידי רענון מחיצות ספציפיות בלבד במקום לעבד את כל מערך הנתונים מחדש.
פונקציה זו חשובה במיוחד כאשר נדרשים עדכונים תכופים לנתונים או כאשר הנתונים מגיעים ממקורות מגוונים ובעלי נפח גדול.
לסיכום
ניתן לפתח מודלים רובסטיים התומכים בכמויות עצומות של נתונים ב PBI באמצעות פיצול המודל ובנייתו לפי הארכיטקטורה המתוארת במאמר זה.
ניהול המודל ב AAS ובשילוב עם PBI מספק פתרון רב עוצמה לבינה עסקית, המאפשר להתמודד עם כמויות גדולות של נתונים תוך שמירה על ביצועים גבוהים ואמינות הנתונים.
בעזרת גישה זו, ניתן לבנות מודלים יעילים ורובסטיים התומכים בצרכים המתקדמים ביותר של ניתוח נתונים ארגוני.






